xetown에서 snoopy관련글을 보다 한번 시도를 해보고 싶어 질문글 올립니다.
아래 페이지 주소에서 2가지 값을 추출 하는 정규식(?)을 어떻게 작성해야 하는지 혹시 도움 좀 받을 수 있을까요?
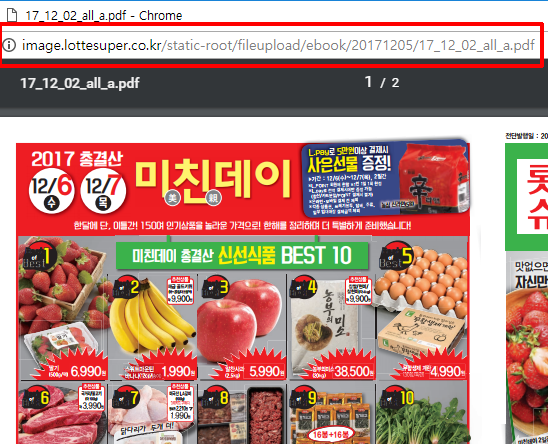
1. 해당 페이지 : http://www.lottesuper.co.kr/handler/cc/Store-Detail?strNo=110684
2. 페이지에서 "가락점" " 인터넷전단보기"에 링크 url 주소를
가락점 http://image.lottesuper.co.kr/static-root/fileupload/ebook/20171205/17_12_02_all_a.pdf 이런 형태로 추출하고 싶습니다.
마트몬
Lv. 8



![1.PNG [File Size:18.0KB/Download:15]](/files/download/link/817542/f9ec65cdb5a010ae15368605c57dd107/1.PNG){kind=link}
![2.PNG [File Size:235.2KB/Download:16]](/files/download/link/817543/d6ce4cc798b2c16515a62cd97c90ffa7/2.PNG){kind=link}
댓글 12
다운받은 데이터 처리는 정규표현식을 사용하여 긁어옵니다.
추가로 pdf 파일 가져오는 방법은 현재 자바스크립트로 다운로드를 처리하고 있습니다.
http://www.lottesuper.co.kr//handler/common/Common-Ebook?_X2_IDENTIFIER_KEY_=_JSON_MESSAGE_&str_no=상점정보 넘버 로 json 받아오시면 pdf링크를 받아 올수있습니다.
답변 감사합니다.
예시들을 찾아보고 아래와 같이 생각을 해봤는데 쉬운게 아니었군요. ^^;
우선 하나의 상점번호에서 상점명과 링크 url 추출한 후 성공하면 전체 상점번호를 넣어 전체 상점에서 원하는 값 ( 상점명과 링크 url ) 추출 하려고 생각했었거든요.
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="Generator" content="EditPlus®">
<meta name="Author" content="">
<meta name="Keywords" content="">
<meta name="Description" content="">
<title>Document</title>
</head>
<body>
<?php
$x=array("110684","상점번호","상점번호"
);
foreach ($x as $value)
{
//변수 초기화
unset($data);
include_once 'Snoopy.class.php';
$snoopy=new snoopy;
$snoopy->fetch('http://www.lottesuper.co.kr/handler/cc/Store-Detail?strNo='.$value);
$result = $snoopy->results;
);
//상점명 추출????
//인터넷 전단 url 링크 추출???
//상점명
echo $data['item'][1][1]. "--" ;
//전단지 URL 출력
echo $data['link']."<br />";
}
?>
</body>
</html>
출렬결과 :
상점명1 -- 전단지 링크 url
상점명2 -- 전단지 링크 url
상점명3 -- 전단지 링크 url
......
$rex="/\<h2 class=\"tit\"\>(.*)\<\/h2\>/";
preg_match_all($rex,$result,$data);
print_r($data);
// 테스트 해보진 않았습니다.
해보시면 제목은 긁어올수있습니다.
$ch = curl_init();
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_URL,$url);
$result=curl_exec($ch);
curl_close($ch);
var_dump(json_decode($result))
<head>
<meta charset="UTF-8">
<meta name="Generator" content="EditPlus®">
<meta name="Author" content="">
<meta name="Keywords" content="">
<meta name="Description" content="">
<title>Document</title>
</head>
<body>
<?php
$x=array("110684","110980");
foreach ($x as $value)
{
//변수 초기화
unset($data);
include_once 'Snoopy.class.php';
$snoopy=new snoopy;
$snoopy->fetch('http://www.lottesuper.co.kr/handler/cc/Store-Detail?strNo='.$value);
$result = $snoopy->results;
$rex="/\<h2 class=\"tit\"\>(.*)\<\/h2\>/";
preg_match_all($rex,$result,$data);
print_r($data);
}
?>
</body>
</html>
첫번째 알려주신 부분은 상점번호 2개를 넣고 테스트 해봤는데 아래와 같이 상점명을 잘 가져 오고 있습니다.
2번째 pdf 부분은 여러 방법으로 게속 시도를 해보고 있지만 코알못이라 어떻게 적용을 해야 할지 전혀 감을 못잡겠는데요 죄송하지만 조금만 더 도움을 주시면 감사하겠습니다. ^^;;
----------------------------------------------------------------------------------------
[ 상점명 출력만 적용 한 결과 ]
Array ( [0] => Array ( [0] =>
가락점
) [1] => Array ( [0] => 가락점 ) ) Array ( [0] => Array ( [0] =>
갈월점
) [1] => Array ( [0] => 갈월점 ) )
-----------------------------------------------------------------------
[ 희망 출력 결과 ]
가락점 -- {"result":{"LAST_LFL_ISSU_DT":"2017.12.06","LFL_URL_ADDR":"http://image.lottesuper.co.kr/static-root/fileupload/ebook/20171205/17_12_02_all_a.pdf"}}갈월점 -- {"result....... }}
상점명3 -- {"result....... }}
....
감사합니다. 2번째 pdf 부분도 어떻게 짜깁기를 하다보니 제대로 출력됩니다.
첫번째 상점명 출력하는 부분에서 마지막 한가지만 더 문의 드리겠습니다.
<?php
$x=array("110684","110980");
foreach ($x as $value)
{
//변수 초기화
unset($data);
include_once 'Snoopy.class.php';
$snoopy=new snoopy;
$snoopy->fetch('http://www.lottesuper.co.kr/handler/cc/Store-Detail?strNo='.$value);
$result = $snoopy->results;
$rex="/\<h2 class=\"tit\"\>(.*)\<\/h2\>/";
preg_match_all($rex,$result,$data);
print_r($data);
}
?>
를 적용하면
Array ( [0] => Array ( [0] =>
가락점
) [1] => Array ( [0] => 가락점 ) ) Array ( [0] => Array ( [0] =>
갈월점
) [1] => Array ( [0] => 갈월점 ) )
출력이 되는데 Array ~~~~ 이렇게 출력되는 부분을 없애려면 어떻게 해야 할지 부탁드리겠습니다.
$data[0][0]; 으로 받아오심 될듯 합니다.